Can AI Get Worse Over Time

Users on online forums noticed that AI bots' performance changes over time. The quality of answers may drop, or a bot may refuse to respond to some questions altogether. The responses we get depend on different factors.
AI bots generate answers based on Large Language Models (LLMs), which are trained on large amounts of information from the web, books, and other sources. A team of computer scientists behind the creation of an LLM integrates the model into a product, which processes requests and responses. To come up with an answer, a system repeats patterns it’s trained on, including how sentences and paragraphs are structured.
AI chatbots and LLMs have been developed by different companies. For example, ChatGPT was developed by OpenAI and uses the GPT language model. Users can choose between the GPT-3.5, GPT-4, GPT-4 Turbo, and the most recent GPT-4o model.
Each new model presents new features and capabilities. What’s interesting is that not only do the capabilities of these models vary from each other, but the same version of the model can change in its accuracy and results.
Take for example the GPT-4, launched in March 2023. According to user reviews, it was surprisingly good at the start but began making mistakes later. On ChatGPT Forums you can see discussions like “WHY ChatGPT 4.0 is getting stupider and stupider,” or “Is Chat GPT getting worse or are my prompts getting worse?” According to users, the bot’s answers were limited, they didn’t provide detailed explanations or failed to catch and fix mistakes.
A study by Stanford confirmed these concerns. Evaluating the GPT-4 and GPT-3.5 models, researchers found that their June version did get significantly more mistakes compared to March. The GPT-4’s mathematics accuracy in answering some problems fell from 98% to 2% during that time. The model failed to respond to questions, like if 17077 is a prime number. It kept saying no, although the correct answer was yes.
Stanford’s study, however, faced disagreements. A response article published by Princeton University computer scientists questioned the methods that were used. While agreeing that GPT’s behavior has changed, the paper mentioned that using another evaluation method, for example testing the model not only on prime numbers, would result in a different picture. At the same time, Princeton University scientists found that the answers did change from March to June. In particular, while in March GPT-4 almost always guessed the number was prime, in the June version it almost always guessed it was composite. The authors believe the interpretation of the model’s behavior as a massive performance drop by the earlier study is incorrect. Instead, they state the bot demonstrated behavioral change affected by regular fine-tuning and prompting. It can still give the correct answer but may require new prompting strategies. According to the Princeton research:
AI chatbots and LLMs have been developed by different companies. For example, ChatGPT was developed by OpenAI and uses the GPT language model. Users can choose between the GPT-3.5, GPT-4, GPT-4 Turbo, and the most recent GPT-4o model.
Each new model presents new features and capabilities. What’s interesting is that not only do the capabilities of these models vary from each other, but the same version of the model can change in its accuracy and results.
Examples of How AI Models’ Performance Declined
It takes time to fully understand the performance and capabilities of an AI model. The model's capabilities become more apparent as more users interact with the system and provide feedback or examples that the system can learn from. Each user interaction requires computational resources, and collectively, these interactions lead to algorithm updates. As a result, there may arise issues, such as response delays, inaccuracies, and failure to respond to certain questions. Typically, the changes are noticeable several months later after the bot’s launch.
Take for example the GPT-4, launched in March 2023. According to user reviews, it was surprisingly good at the start but began making mistakes later. On ChatGPT Forums you can see discussions like “WHY ChatGPT 4.0 is getting stupider and stupider,” or “Is Chat GPT getting worse or are my prompts getting worse?” According to users, the bot’s answers were limited, they didn’t provide detailed explanations or failed to catch and fix mistakes.
A study by Stanford confirmed these concerns. Evaluating the GPT-4 and GPT-3.5 models, researchers found that their June version did get significantly more mistakes compared to March. The GPT-4’s mathematics accuracy in answering some problems fell from 98% to 2% during that time. The model failed to respond to questions, like if 17077 is a prime number. It kept saying no, although the correct answer was yes.
Stanford’s study, however, faced disagreements. A response article published by Princeton University computer scientists questioned the methods that were used. While agreeing that GPT’s behavior has changed, the paper mentioned that using another evaluation method, for example testing the model not only on prime numbers, would result in a different picture. At the same time, Princeton University scientists found that the answers did change from March to June. In particular, while in March GPT-4 almost always guessed the number was prime, in the June version it almost always guessed it was composite. The authors believe the interpretation of the model’s behavior as a massive performance drop by the earlier study is incorrect. Instead, they state the bot demonstrated behavioral change affected by regular fine-tuning and prompting. It can still give the correct answer but may require new prompting strategies. According to the Princeton research:
One important concept to understand about chatbots is that there is a big difference between capability and behavior. A model that has a capability may or may not display that capability in response to a particular prompt. It is little comfort to a frustrated ChatGPT user to be told that the capabilities they need still exist, but now require new prompting strategies to elicit.
GPT isn't alone in its struggle. Users of other AI bots, including Anthropic’s Claude, pointed out worsening performance, too. They mention that since the app’s release, it became slower, and less accurate.
AI models like ChatGPT learn not only from data they are trained on but also adjust and learn from user inputs. If you regularly use ChatGPT, you have probably noticed that the app asks for feedback. For example, on ChatGPT, you can dislike the answers that are not helpful and provide specific feedback on why. OpenAI removed the like button, focusing more on negative responses and nuanced feedback. It can sometimes deliver two possible versions of a response and ask which one you prefer to help improve its language generation capabilities.
ChatGPT adjusts its performance based on collected user feedback. However, doing so in a way that everyone likes is practically impossible.
Another crucial factor influencing AI models' responses is the implementation of safety guidelines. Programs increasingly refuse to answer sensitive questions to avoid bias and harmful outputs. On the positive side, this approach enhances safety and ethical standards, but it can also limit the system's capabilities in certain contexts.
For example, Claude refuses to identify people in photos due to privacy and safety policies. To test the app, we attached a photo of Michael Jackson, asking the bot to tell us who it was. Claude explained that it can’t name the person “per its guidelines.” However, it provided a descriptive hint, acknowledging that the image depicted "an incredibly influential and celebrated figure in the music industry whose artistry and performances captivated audiences worldwide." This shows that while Claude recognized Michael Jackson, it is trained to refrain from directly answering such questions.

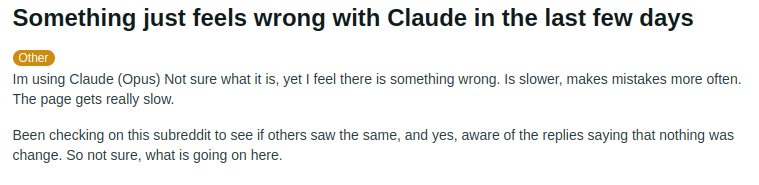
User review on Claude. Source: reddit.com
Why AI Models Become Worse Over Time?
Generally, AI apps including ChatGPT and Claude are closed-source, meaning full details about how they are trained and work are not available. Although the exact reasons behind the deteriorating performance are hard to evaluate, there are several factors that make an impact. Among them is the challenge of fine-tuning large language models in different directions without compromising any of their capabilities. The Stanford research also mentions:
Improving the model’s performance on some tasks, for example with fine-tuning on additional data, can have unexpected side effects on its behavior in other tasks. Consistent with this, both GPT-3.5 and GPT-4 got worse on some tasks but saw improvements in other dimensions.
The study also found changes in how the models reason and the level of detail in their answers.
AI models like ChatGPT learn not only from data they are trained on but also adjust and learn from user inputs. If you regularly use ChatGPT, you have probably noticed that the app asks for feedback. For example, on ChatGPT, you can dislike the answers that are not helpful and provide specific feedback on why. OpenAI removed the like button, focusing more on negative responses and nuanced feedback. It can sometimes deliver two possible versions of a response and ask which one you prefer to help improve its language generation capabilities.
ChatGPT adjusts its performance based on collected user feedback. However, doing so in a way that everyone likes is practically impossible.
Another crucial factor influencing AI models' responses is the implementation of safety guidelines. Programs increasingly refuse to answer sensitive questions to avoid bias and harmful outputs. On the positive side, this approach enhances safety and ethical standards, but it can also limit the system's capabilities in certain contexts.
For example, Claude refuses to identify people in photos due to privacy and safety policies. To test the app, we attached a photo of Michael Jackson, asking the bot to tell us who it was. Claude explained that it can’t name the person “per its guidelines.” However, it provided a descriptive hint, acknowledging that the image depicted "an incredibly influential and celebrated figure in the music industry whose artistry and performances captivated audiences worldwide." This shows that while Claude recognized Michael Jackson, it is trained to refrain from directly answering such questions.
Claude refuses to identify Michael Jackson in the photo due to safety measures. Source: claude.ai
What Will Happen in the Future?
AI models’ performance not only can improve but also decline over time. The behavior of future AI applications is largely uncertain. It depends on how developers overcome the challenge of fine-tuning models without compromising existing abilities, whether there will be standards to train AI models, and how ethical constraints will impact the quality of answers.

Author
Web3 writer and crypto HODLer with a keen interest in market trends and recent technologies.